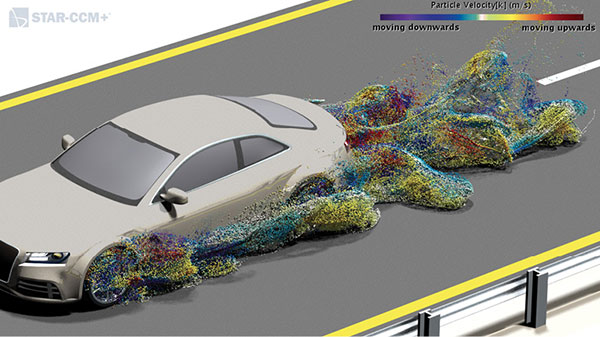
Using Siemens software to simulate how weather conditions like rain, snow or dust can adversely affect autonomous driving sensors. The software uses GPU acceleration to speed up Lagrangian Mass Particle (LMP) simulation methods. Images courtesy of Siemens.


Latest News
March 1, 2020
In 2009, graphics processing unit (GPU) maker NVIDIA hosted its first GPU Technology Conference (GTC) in the Fairmont Hotel in San Jose, CA. Stepping up to the stage in the hotel’s ballroom, NVIDIA CEO Jen-Hsun “Jensen” Huang unveiled what he called “the soul of a supercomputer in the body of a GPU.” He was talking about the new GPUs built under the Fermi architecture, the basis for the company’s subsequent GeForce and Quadro GPUs.
Fermi is “a brand new architecture designed from the ground up to be a computer first … [It treats] computer graphics and parallel computing as equal citizens,” Huang explained. This was a watershed moment in the GPU’s evolution.

Up to this point, the GPU was primarily a coprocessor to boost graphics performance—a piece of special hardware that made your explosions more spectacular in PC games. From this point on, the GPU would take on more and more of the type of computing usually done by the CPU. NVIDIA’s compute unified device architecture (CUDA) programming language for GPU computing also laid the foundation for the transition. That opened the door to GPU-accelerated simulation, which harvests the GPU’s superior number of processing cores to tackle massively large simulation problems.
In 2009, the premier GTC launched with 1,500 attendees. A decade later, GTC 2019 was attended by 9,000, NVIDIA verified. The company expects GTC 2020’s attendance to reach 10,000. Similarly, the role of the GPU in simulation has significantly expanded over the past decade.
GPU vs. CPU
To be GPU-accelerated means to enlist the many processing cores in the GPU for general computing tasks. Therefore, tasks that are highly parallel—those that can be divided and simultaneously processed on many cores—tend to benefit more from GPU acceleration (for example, real-time rendering). By contrast, tasks that must be completed sequentially in a specific order, such as CAD geometry modeling, get more benefit from a faster CPU.
“Within the context of our integrated multiphysics solutions, our focus is on computational fluid dynamics [CFD], where for many years incremental improvements in performance have been realized by utilizing GPUs to perform the linear system solve. The real benefit comes when the full computational algorithm, including assembly of the linear system, is suitably implemented for GPUs,” notes Matt Godo, senior manager, Simcenter STAR-CCM+ Technical Product Management, Siemens Digital Industries Software.
“This is quite naturally done for things like discrete element method (DEM), smoothed particle hydrodynamics and Lattice-Boltzmann technologies. It’s also been shown recently that Navier-Stokes solvers, if properly architected, can obtain similar significant speedups on GPUs,” he adds.
In 2016, Siemens acquired CD-adapco, maker of the STAR-CCM+ multiphysics simulation software suite, to add to its roster of simulation and test software solutions. The software is widely used by engineers to optimize and test their designs across a broad range of use cases such as single-phase and multiphase flows, aero and hydrodynamics, heat transfer, electromagnetics and fluid-structure interactions.
Not Just CFD
In late 2018, ANSYS launched ANSYS Discovery Live, primarily targeting design engineers. Different from traditional simulation software targeting experts and sophisticated users, Discovery Live emphasizes speed. The software is written to compute and display simulation results in real-time or near-real-time speed. The speed comes primarily from GPU acceleration, implemented through NVIDIA’s CUDA framework. The software currently runs exclusively on NVIDIA GPUs.
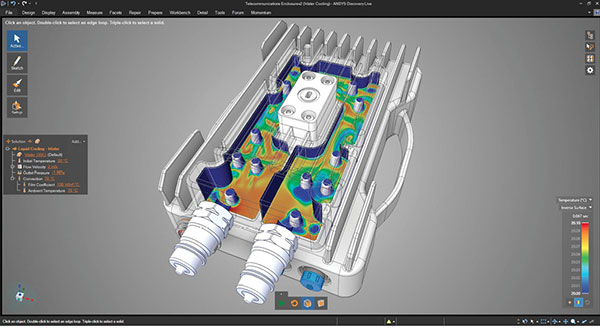
“We found that almost all types of simulation can be accelerated by the GPU,” notes Mark Hindsbo, VP and GM, ANSYS. “Our Discovery Live, for instance, runs natively on the GPU. We have structural, thermal, fluid and electrostatic simulations running on the GPU.”
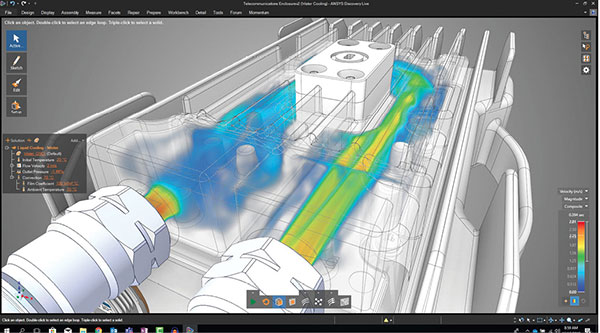
Artificial intelligence training and machine learning—newer types of computation—are made possible by GPU computing. It’s technically possible to run the same types of computation on CPU clusters, but the dramatic speedup possible and the large dataset involved make GPU clusters a more practical choice.
Legacy Code and the GPU
The origins of many modeling and simulation software for the engineering sector date all the way back to the 1980s and 1990s, when the yearly CPU speed increases (better known as Moore’s law) was the bankable rule.
Many of the program codes, therefore, were architected to harvest the CPU’s processing speed; GPU acceleration is a more recent phenomenon. Rewriting CPU-straddling codes into GPU-friendly codes is no small feat. In some cases, writing brand new programs may prove easier than revising the legacy code.
“Many simulation software vendors are still investigating how and if to switch to GPUs,” observes Joe Walsh, CEO and cofounder of the ASSESS Initiative. “The challenge is, to get these performance improvements, significant architectural changes are needed in the software. Look for new applications built from scratch on GPUs rather than porting of existing large simulation applications.”
ASSESS, which stands for Analysis, Simulation & Systems Engineering Software Strategies, is a membership-based industry group. It holds annual congresses that bring together simulation software industry leaders and insiders to swap knowledge, present findings and discuss challenges. The ASSESS 2020 Congress is set for November 2-4, in Braselton, GA.
New Licensing Models Emerging
The effects of GPU acceleration may also spill into simulation software licensing. GPU acceleration encourages engineers to run design of experiments (DOE)—evaluating multiple design options simultaneously. It also plays a role in topology optimization and generative design software, which uses algorithms to compute and propose suitable design options based on user-stated requirements. But it also challenges the design software industry that traditionally charges users by seat or node (machines operating the software), not by consumption, as software-as-a-service vendors typically do.
Vendors such as ANSYS introduce high-performance computing (HPC) licensing to address the shift. “Each GPU is treated as a CPU core in terms of licensing, so users can gain higher productivity through GPU simulations,” writes ANSYS on its homepage for HPC licensing.
“The improved performance can enable near-real-time response, opening the market for significantly broader usage. To enable this broader usage, new pricing models will be explored,” says Walsh.
Boosting Performance
In benchmark results published by NVIDIA and ANSYS titled, “NVIDIA Quadro Enabling ANSYS Discovery Live,” running the same test job with NVIDIA Quadro RTX 4000 (2304 CUDA cores) provides more than 3x in performance boost over the older generation Quadro M4000 (1664 CUDA cores).
Switching to Quadro RTX 6000 (4608 CUDA cores) results in nearly 4.5x in performance boost over Quadro M4000.
These stats suggest that the more processing cores are in the GPU, the higher the speed bump. But there’s a point at which the performance boost becomes less dramatic, due to how much a job can be parallelized or how well the software is written to harvest the GPU.
“The wisdom of Amdahl’s law also comes into play here. We can reasonably expect performance gains to plateau,” warns Godo. This rule refers to a principle by computer scientist Gene Amdahl, who came up with a formula for estimating theoretical speedup in parallel computing workloads. Amdahl stated that “speedup is limited by the total time needed for the sequential (serial) part of the program” (Bit.ly/2urVpzw).
“ANSYS Discovery Live can take advantage of two GPUs—one for general compute, the other for rendering visuals. The performance boost varies from application to application, but with today’s software, you’ll probably see [the] most significant performance improvements with one or two GPUs,” says Hindsbo.
“But it’s also important to look at the amount of memory,” he adds. “How big a problem can you load into the GPU? If you have to go out of the GPU to load or save data, you pay a high performance penalty.”
Fitting Into the GPU Memory
A GPU with more memory allows larger computing jobs to be efficiently loaded and processed. Therefore, if the size of the model or dataset exceeds the memory available on the GPU, the memory shortage undermines the GPU cores’ ability to divide and conquer the job itself.
Hindsbo believes the best approach is the hybrid approach—to get the best available CPU and GPU. In his view, investing in one to the exclusion of the other is not wise.
“When planning for tomorrow’s engineering compute platform, both on the desktop and in the cluster, you should be thinking hybrid GPU and CPU,” he explains. “The majority of the applications today are legacy applications written for the CPU, so you cannot realistically get away from the CPU. Even if you started from scratch, there are certain things the CPU will be better at than the GPU. Similarly, having no GPU computing will be a major deficiency both today and tomorrow,” he adds.
More Ansys Coverage
More ASSESS Initiative Coverage
More NVIDIA Coverage
More Siemens Digital Industries Software Coverage
Subscribe to our FREE magazine, FREE email newsletters or both!
Latest News
About the Author
Kenneth Wong is Digital Engineering’s resident blogger and senior editor. Email him at [email protected] or share your thoughts on this article at digitaleng.news/facebook.
Follow DE