Resolving Manufacturing’s AI Dilemma
New algorithm training processes could lead to more AI on the factory floor.

Fig. 1: Machine and deep learning promise to provide manufacturers with insights to achieve efficiency, but unavailability of “good data” has prevented companies from leveraging the technologies. Image courtesy of Sight Machine.


February 1, 2022
What prevents artificial intelligence (AI) from having a larger role in the manufacturing sector? The answer is data. Raw manufacturing data is a hodgepodge of formats, generated by an eclectic assortment of systems that use various metrics. Sometimes the data is transmitted in a streaming process and measured as a time series. At other times, it comes in the form of discrete data.
Compounding the chaos, the number of variables involved in production processes are often measured in the thousands.
This chaos and the pervasiveness of “bad data” limit the occasions in which AI/machine learning (ML) algorithms can be trained efficiently and cost-effectively. This, however, may be about to change.
New ways to collect and process training data promise to open the door for greater AI involvement on the factory floor (Fig. 1). Whether these are competing approaches or complementary techniques is not yet determined. Either way, AI’s prospects are looking up, but the technology’s advancement will by no means be an easy process.
In Search of Good Data
The first step to address manufacturing’s AI dilemma is for companies to change how they view data.
“We’re coming out of an era in which big data meant that you didn’t need good data quality,” says Kurt DeMaagd, chief AI officer and co-founder of Sight Machine. “You just had to throw lots of data at the problem. We’re now entering an era in which manufacturers must operate on the principle that you need good data as the foundation for good AI/ML analysis.”
Though good data is not often readily available. “Most industrial data isn’t great,” says Luke Durcan, EcoStruxure director at Schneider Electric. “It’s inconsistent and uncontextualized. For data to mean anything, it must be fully contextualized around the process. Regrettably, no one has that data right now—or few do.”
Yet it was not always practical to obtain good data—even when it was available. It took too long to acquire, cost too much to extract and required staff expertise that few companies had. Furthermore, until recently, engineers simply didn’t have the data infrastructure or process constructs to fully use AI technology. These shortcomings hamstrung those seeking to harness the AI’s power.
For example, supervised learning—one of the most common approaches for training machine learning (ML) algorithms—can be a laborious, time-consuming process. The ML algorithm is trained with data consisting of example inputs paired with the correct outputs. Depending on the use case and the existence of pretrained models, teams need anywhere from hundreds to tens of thousands of training examples to build a robust algorithm, which makes this technology impractical for many companies.
These constraints meant that ML algorithms often could only infer outcomes. This level of performance, however, does not meet the exacting standards of industrial applications.
“When people and safety are concerned, inference simply does not work,” says Durcan.
To produce algorithms that can deliver the precision and accuracy that manufacturers requires, the analyst not only must be able to cost-effectively collect enough data to train the algorithm, but must also have a data set that covers all relevant variables. Without adequate training data and this level of contextualization, the algorithm is useless.
Building Data Foundations
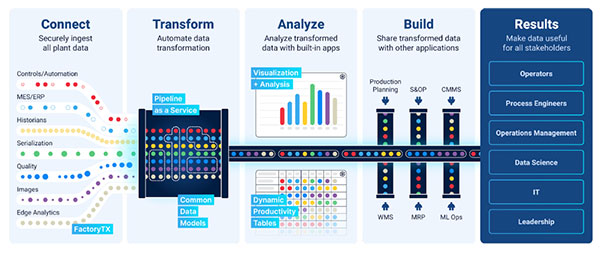
To train ML algorithms, analytics software providers have begun to develop data pipelines (Fig. 2) that aim to transform the patchwork of data, metrics and measurements generated on the factory floor into actionable, structured data. These mechanisms promise to enable manufacturers to create data foundations upon which they can build AI analytics and productivity improvement programs, opening the door for expanded use of ML on the factory floor (Fig. 3).
“We see important work underway in AI-enabled data pipelines, which use ML to make sense of manufacturing environments containing tens of thousands of variables,” says DeMaagd. “The objective is to use AI to create a reusable data set that is good not just for one specific problem, but instead can be the platform for many different applications.”
Data preparation is a key function of these platforms. This means the manufacturer tries to understand which variables are useful and which are not—essentially attempting to understand the difference between bad data and interesting anomalies. Ultimately, the goal is to create a model of what a good data set looks like.
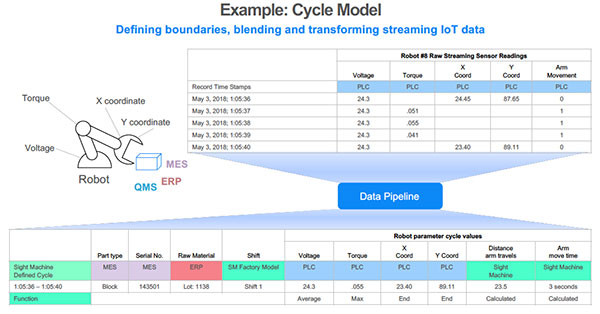
Broken down into incremental steps, this process can take many different forms. Some data preparation functions, however, are common to most applications. For instance, analysts often begin with raw data conversion into useful formats. An example of this might be translating an alarm signal that contains the module location, event severity and a numeric code into a description.
After this step, the data scientist often must merge data sets from different systems. This can be particularly challenging when the sources have different granularity. For example, subsecond data from a programmable logic controller may be blended with quality/test data taken from hourly samples.
Analysts must also contend with missing data. Here, corrective measures can range from interpolating between data points when there are small gaps, to filtering out data when there are modest gaps, to removing low-quality variables from the data set.
Data preparation also calls for bad data detection. In this step, the analyst searches for changes in variables, or they try to understand when outliers represent interesting production anomalies or simply constitute bad sensor readings or inadequate data collection.
At this stage of algorithm development, the analyst will also identify and document the various data types, such as numeric, text or Boolean. This is required because not all analysis methods work on all types of data. The analyst may have to re-encode some of the data or simply ignore it because it is not applicable.
Tapping the Digital Twin
Digital twin advocates have proposed another approach to obtain good training data. Here, the analyst relies on digital twin simulations of the machine or process in question to generate training data.
This not only enables training when other sources are impractical or the data simply isn’t available, but it also promises to shorten the overall training process. Manufacturers can also test the trained algorithms on the virtual model and run anomaly detection on the twin to determine if the algorithms can detect anomalous behavior.
An example of this is the optimization of an industrial robot.
“In the virtual environment, the robot, parts and sensors are replaced with virtual ones,” says Vincent Guo, director of business development at Siemens Digital Industries Software. “Instead of devoting time and resources to setting up the equipment, capturing voluminous images and manually annotating them, it is now possible to do so within a virtual environment.”
This approach works on relatively simple applications, but when algorithms are required for less-structured, more complex machines or processes, much larger amounts of training data and long training periods are needed.
In cases like these, the analyst can turn to reinforcement learning—a process of learning by trial and error. The drawback with reinforcement learning that uses a physical training environment is that it requires millions of attempts before solving a task, requiring an unrealistic amount of time.
Manufacturers can work around this obstacle by combining reinforcement learning with deep learning and digital twin. This approach promises to mitigate the problem by training the algorithm using virtual simulation, accelerating the time required for training and reducing development costs in the process.
For both techniques to work, however, all sensory inputs must be properly represented and simulated within the virtual environment, and therein lies the catch. Training data generated by virtual simulation will only be as good as the digital twin used to train the algorithm. If the digital twin incorporates inaccurate data or has missing important variables or data, the resulting algorithm is flawed. At which point, the engineer or analyst must return to more traditional ML tools and techniques.
Adding a Touch of Real World
Whether the manufacturer adopts the data pipeline approach or leverages digital twin, building a good data set doesn’t end with data preparation. It’s followed by simulation and test, and then deployment.
But even after the analyst completes these traditional steps, they must still re-examine the training data and make any required changes to the data set to increase accuracy. This data validation step is accomplished by using ground truth data—real-world data collected from actual machines or processes already in operation.
This validation relies not only on the quality of the ground data, but also on the quantity of information collected. A common mistake that degrades the effectiveness of ground truth data is when the analysts do not take the time to identify all associated parameters and fully understand the kind of data required. Failure to methodically work through this process prolongs the algorithm development process.
After building the ground-truth data set, the analyst breaks down the data into two smaller data sets: training and testing data. The analyst trains the ML algorithm using the training data set, and tests the model’s effectiveness using testing data.
Things can get tricky, however, when the analyst takes results from failed experiments—results that may not align with the ML predictions—and uses them to improve future results.
“We typically see this problem when there is a new combination of inputs,” says DeMaagd. “The ML algorithm attempts to extrapolate and gets the answer wrong. This is why it is important to have a real-time data feed continuously retraining your system. Then as your system slowly drifts, or as you collect more information about particular combinations of settings, your ML algorithm is constantly updating to factor in that new information.”
Digital Twin Validation
Another validation approach uses digital twin technology. Once the manufacturing machinery or process is physically deployed, the analyst switches to data that has been extracted from the real-world operating environment and incorporated in the twin.
The analyst can then correlate this data with the training data generated by the virtual twin. This promises to enhance the accuracy of the algorithm and improve the fidelity of the digital twin.
“The digital twin is crucial to implementing machine learning grounded in real-world data,” says Guo. “Instead of creating a time-consuming and costly prototype and then trying to train it with physical objects, much of the training can be done virtually using a digital twin.”
Using Reality as a Benchmark
Both approaches share one common principle: Ground truth data provides the link between the theoretical and physical worlds necessary to ensure the effectiveness and precision of ML algorithms.
“With manufacturing, you need to actually test your results in production rather than strictly using the traditional statistically oriented machine learning accuracy metrics,” says DeMaagd.
The real-world feedback loop provided by ground truth data represents the key ingredient required to make sense of shop floor data. “Ground truth is essential,” says Durcan. “It’s the key part of the contextualization conversation that is missing.”
Finding AI’s Sweet Spot
Manufacturers are still trying to find the applications in which machine and deep learning deliver the greatest value. But these are still relatively early days.
To understand where AI is in the process of carving out its role on the shop floor, look at the focus of current development efforts. Manufacturers have been paying more attention to using these advanced systems earlier in the analysis process. Before this can occur, however, some work must be done on AI technology.
“Before you can analyze problems like uptime, throughput and quality effectively, at scale, you must have a good data set,” says DeMaagd. “So now we’re seeing companies that are stepping in to say, “How can we use AI not to solve the end problem but to help to create a good data set, which can then be used to solve all of these other problems?”
The real measure of AI advancement in manufacturing will not be found in areas such as predictive maintenance or quality inspection. Instead, it will be seen in the quality of the data sets with which it works. After addressing these issues, many doors will fling open for the manufacturing community.
More Siemens Digital Industries Software Coverage
Subscribe to our FREE magazine, FREE email newsletters or both!