

March 23, 2020
Reinforcement learning is a type of machine learning that can help solve tough decision-making problems. But to be able to understand the potentialrole of this technology in a project, we need to answer three key questions:
- What is reinforcement learning?
- When do I use reinforcement learning?
- What workflow should I follow to solve my reinforcement learning problem?
What Is Reinforcement Learning?
Reinforcement learning helps a computer agent learn a behavior through repeated trial-and-error interactions with a dynamic environment. This approach enables the agent to make a series of decisions that maximize a reward metric for the task without being explicitly programmed to do so and without human intervention.
Consider parking a vehicle using an automated parking system. The goal of this task is for the vehicle computer (agent) to park in the correct parking spot. Fig. 1 shows the general overview of a reinforcement learning system. In this scenario, everything outside the agent, including the vehicle dynamics, surrounding vehicles, weather conditions, etc., is part of the environment. During training, the agent uses readings from sensors such as cameras and GPS, and lidar (observations) to get information about the environment state. To learn a policy, i.e., how to generate the correct actions like steering and braking, from these observations, the agent repeatedly tries to park the vehicle using a trial-and-error process, attempting to maximize a reward signal. The reward is used to evaluate the goodness of a trial and to guide the learning process.
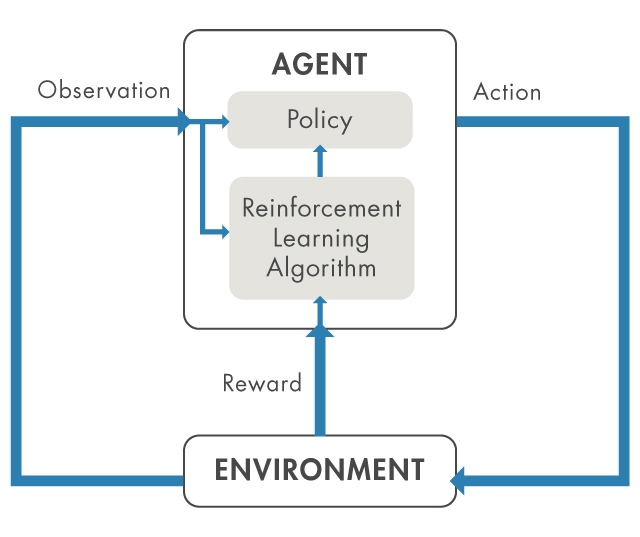
Based on the collected observations, actions and rewards, a training algorithm is responsible for tuning the agent’s policy. After training, the vehicle’s computer should be able to park using only the tuned policy and sensor readings.
When Do I Use Reinforcement Learning?
Several reinforcement learning training algorithms have been developed. Many of these are based on deep neural network (DNN) policies that allow the use of reinforcement learning in applications, such as automated driving (Fig. 2), that are otherwise challenging to tackle with traditional algorithms. For example, traditional control design based on camera feedback is challenging because there is a lot of preprocessing required, e.g., for feature extraction, before the camera frames can be effectively used in a feedback loop. With DNNs, however, the feature extraction step becomes part of the neural network policy, allowing for end to end solutions.
On the other hand, the challenge with DNN algorithms is their complexity—often consisting of millions of parameters—which makes it impossible to explain the decisions taken by the network and hard to establish formal performance guarantees. One additional factor to considering reinforcement learning is that it is not sample efficient. For projects that require quick execution when limited training time is available, the training-intensive reinforcement learning approach presents additional barriers. For instance, training time for this approach can range from minutes to days even for relatively simple applications. Finally, the large number of design decisions that need to be made to set up a reinforcement learning problem makes correct problem set up tricky, often requiring multiple iterations to get right.

What workflow should I follow to solve my reinforcement learning problem?
Here’s a general reinforcement learning workflow for training an agent (Fig. 3).
- Formulate Problem—Define the task for the agent to learn, including how the agent interacts with the environment and any primary and secondary goals the agent must achieve.
- Create Environment—Define the environment within which the agent operates, including the interface between agent and environment and the environment dynamic model.
- Define Reward—Specify the reward signal that the agent uses to measure its performance against the task goals and how this signal is calculated from the environment.
- Create Agent—Create the agent, which includes defining a policy representation and configuring the agent learning algorithm.
- Train Agent—Train the agent policy representation using the defined environment, reward, and agent learning algorithm.
- Validate Agent—Evaluate the performance of the trained agent by simulating the agent and environment together.
- Deploy Policy—Deploy the trained policy representation using, for example, generated GPU code.
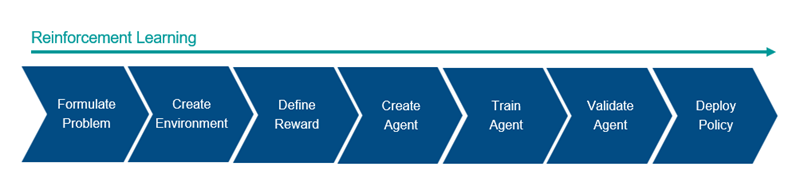 Fig. 3.
Fig. 3.Training an agent using reinforcement learning is an iterative process. Decisions and results in later stages may require returning to an earlier stage in the learning workflow. For example, if the training process does not converge to an acceptable policy within a reasonable amount of time, one of these may need updating before retraining the agent:
- Training settings
- Learning algorithm configuration
- Policy representation
- Reward signal definition
- Action and observation signals
- Environment dynamics
Today, tools focused on reinforcement learning can help you ramp up and implement controllers as well as decision-making algorithms faster.

Regardless of the choice of tool, if you are interested in using reinforcement learning technology for your project but have not used it before, the right place to start is by answering these three questions to determine if it is the right approach for you.
Emmanouil Tzorakoleftherakis is a product manager at MathWorks.
More MathWorks Coverage
Subscribe to our FREE magazine, FREE email newsletters or both!


